李远宁:语音感知与表达的神经机制、模型与脑机接口
撰稿:安靖民 审核:王茜

2024年5月30日,上海科技大学李远宁助理教授应北京大学IDG麦戈文脑科学研究所邀请,就人脑语音加工的神经机制以及深度学习模型与人脑对齐等研究进行了精彩报告。本期学术笔记根据其题为“语音感知与表达的神经机制、模型与脑机接口”的学术报告整理而成。
李远宁助理教授的主要研究方向为计算和认知神经科学,主要研究内容包括语言相关认知过程的神经机制,神经编码和解码模型,语言脑机接口等。此次讲座的主题围绕语音信号的神经编码和解码展开,李教授详细介绍了他们如何利用深度学习模型来分析和重建大脑中的语音信号,以及这些研究如何应用到脑机接口中。
1. 语音感知在人脑听觉回路与神经编码模型的相似性
李远宁助理教授首先介绍了语音感知的神经编码研究从基于语言学理论的模型框架到完全采用数据驱动的端到端深度学习模型的转变。传统的神经编码模型主要通过电刺激等实验手段确定特定神经区域对特定感知或认知特征的响应,并用数学或统计模型解释这些特征与神经活动的关系。深度学习模型相较传统的神经编码模型在很多语音识别任务上已经达到接近人类的识别水平,然而这类模型的内部特征表达呈现出复杂的动态模式,其内在的表征与计算难以直接被理解与解释。他们假设,既然这些模型与大脑听觉回路能够接收相同的语音输入,并执行相似的认知功能,那么这两者之间应该也存在计算和表征上的相似性。
于是,李远宁助理教授及其合作者们在1000小时英文自然语音上训练了多种不同的深度学习模型,包括基于卷积神经网络(convolutional neural network, CNN)、以及Transformer等不同架构,通过比较基于这些模型建立的神经编码模型在听觉通路不同节点的神经活动预测表现,他们发现:端到端的语音预训练网络的层级结构,与听觉回路的层级结构之间确实存在着很大的相似性。在语音感知过程中,人脑中的颞横回(Heschl's gyrus,HG)首先从复杂的声学语音信号中提取辅音和元音等基本语音元素进行初阶加工,随后这些元素被传递到颞上回(superior temporal gyrus,STG)参与语音的高阶听觉处理 (Bhaya-Grossman and Chang, 2022; Mesgarani et al., 2014)。研究发现,Transformer模型在建模高级听觉皮层(如STG)表现最佳,其底层和高层特征分别与初级和高级听觉皮层的特征相对应(图1)。具体来说,前部Transformer层更好地对应于听神经(auditory nerve,AN)、下丘(inferior colliculus,IC)听觉神经元和颞横回初级听觉皮层,而中后部的Transformer层与颞上回高级听觉皮层相对应。

图1. CNN和Transformer模型对大脑不同区域的建模表现,从左到右依次对应AN\IC\HG\STG。model:使用生物物理模型模拟的神经元活动;ECoG(Electrocorticography):从人脑对应区域实际记录的皮层脑电信号 (Li et al., 2023)
进一步研究发现,模型在不同层级提取的特征与大脑中不同脑区的激活模式相对应。例如,模型的底层特征主要反映语音的声学信息,如频谱、能量等,与初级听觉皮层的激活模式相似;而模型的高层特征则更多地反映语音的语义信息,如词义、句子含义等,与高级听觉皮层的激活模式相似。
2. 上下文信息、跨语言感知与大脑信号重建
李远宁助理教授强调了上下文信息在语音感知中的重要性,指出大脑对语音的处理不仅依赖于当前的语音信号,还受到先前语音信息的影响。研究发现,深度学习模型的注意力机制与大脑对上下文信息的处理有关。在初级听觉皮层,模型对局部语音特征(如音素)更敏感,而在高级听觉皮层,模型对长距离上下文依赖(如词、短语、句子)更强(图2,BPS:用于衡量模型预测大脑神经活动的能力,其值越高代表模型的预测能力越强;AS:注意力权重矩阵和模板之间的平均相关系数,其值越高表示模型对特定上下文信息的关注程度越高)。这与人脑对语音的处理过程一致,即从底层的声学特征到高层的语义和句法特征的逐步整合。

图2. Transformer模型在初级听觉皮层(HG, f图)中对局部语音特征更敏感,在高级听觉皮层(STG, g图)中对上下文依赖更强 (Li et al., 2023)
此外,李远宁助理教授还讨论了跨语言语音感知的神经机制。研究发现,不同语言背景的模型对不同语言的语音信号具有特异性响应,这与人脑的跨语言语音感知现象一致。例如,中文母语者在听中文语音时,其大脑活动与中文语音模型的表征更相似;而英文母语者在听英文语音时,其大脑活动与英文语音模型的表征更相似。这表明,大脑对语音的处理受到语言经验的调节,不同语言背景的人在语音感知上存在差异。这种跨语言差异不仅体现在大脑的神经活动上,也反映在深度学习模型的表征特征中。
基于深度学习模型对大脑语音表征的理解,李远宁助理教授还分享了他们从大脑信号中重建语音的工作。他们设计了一个模块化的多流神经网络模型,用于从颅内记录中直接合成声调语言语音(图3)。该模型将整个模型分为两部分:标签生成器和合成器模型。标签生成器包括音调标签生成器和音节标签生成器。合成器模型结合了标签生成器的输出和非区分性语音电极的输入,生成语音的梅尔频谱图,最后合成为声波。该模型利用双流结构分别解码声调和音节,并结合非区分性语音电极的信息合成语音,相较于传统的深度神经网络模型,在有限的训练数据下实现了更高的准确率并合成出质量更高的语音。

图3. 语音合成多流神经网络模型 (Liu et al., 2023)
3. 语音生成的神经机制与声调调控
李远宁助理教授还介绍了语音生成的神经机制。语音生成的过程涉及到多个发声器官的协同运动,这些运动受到大脑运动皮层(motor cortex)的控制。研究发现,运动皮层中的不同区域分别控制着不同的发声器官,如嘴唇、舌头、下巴等。通过记录和分析运动皮层的神经活动,可以解码出发声器官的运动模式,从而重建语音。
对于汉语等声调语言,声调是语音的重要组成部分。声调由声带的张力和振动频率决定,其准确控制对于区分词义至关重要。他们的研究发现,喉部运动皮层(laryngeal motor cortex,LMC)中存在两类不同的神经元,分别负责音调的上升和下降。这种双向调控机制使得声带能够在短时间内快速调节张力,从而产生不同的声调。此外,直接对LMC进行电刺激,可以在受试者发音时诱发音调的上升或下降,进一步证实了LMC在声调控制中的因果作用(图4)。此外,研究还发现,大脑对声调的编码不仅依赖于运动皮层,还涉及到听觉皮层等其他脑区。
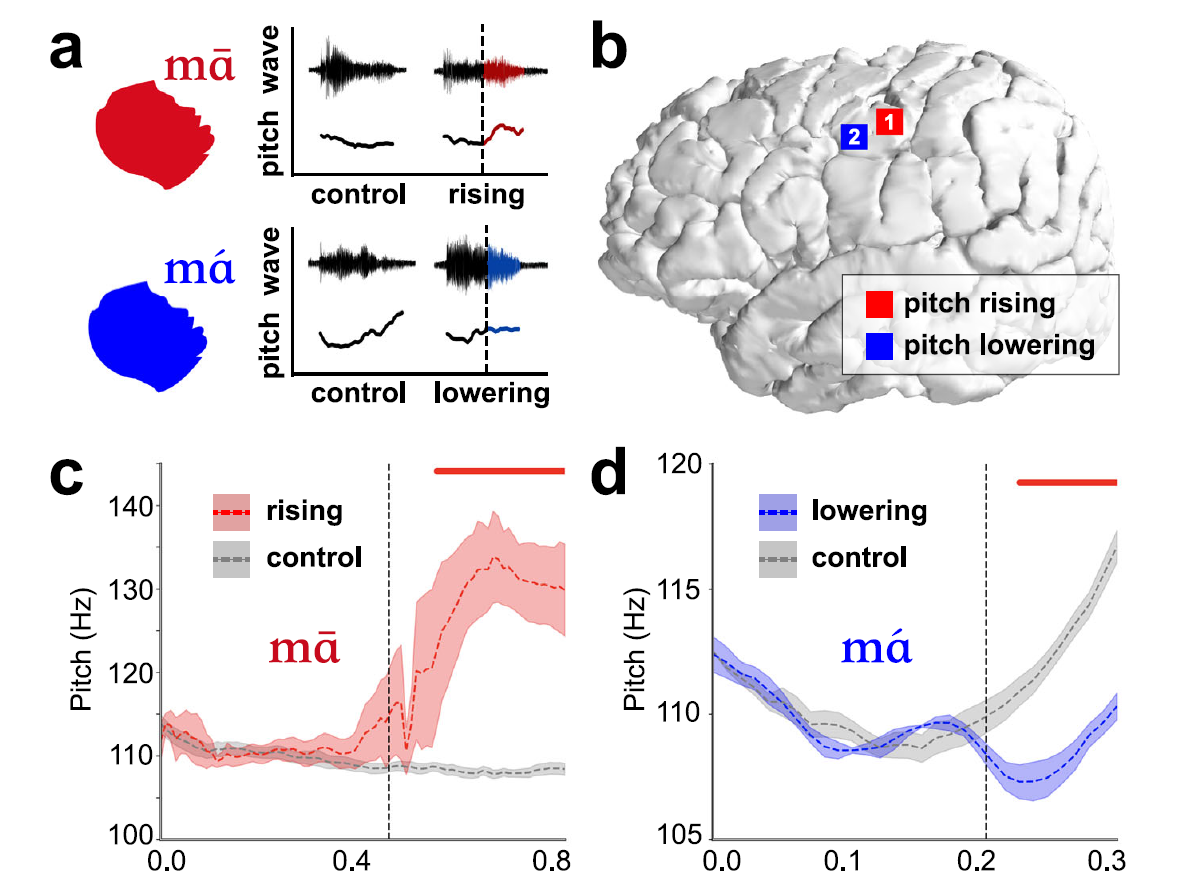
图4. 直接刺激LMC可以引起受试者发音音调的上升或下降 (Lu et al., 2023)
总结
李远宁助理教授的讲座深入浅出地介绍了语音信号的神经编码与解码研究的最新进展,重点探讨了深度学习模型与人脑语音表征之间的相似性。研究发现,深度学习模型不仅可以有效地识别语音,还可以在一定程度上模拟人脑的语音感知过程,并为从大脑信号中重建语音提供了新的思路。此外,研究还揭示了大脑对声调的编码和调控机制,为声调障碍的诊断和治疗提供了新的方向。总而言之,李远宁助理教授的这些研究成果不仅加深了我们对大脑语音处理机制的理解,也为开发更智能、更自然的语音交互技术以及更有效的语言康复治疗方法提供了重要的理论基础。
参考文献
1. Bhaya-Grossman, I., Chang, E.F., 2022. Speech Computations of the Human Superior Temporal Gyrus. Annu. Rev. Psychol. 73, 79–102. https://doi.org/10.1146/annurev-psych-022321-035256
2. Li, Y., Anumanchipalli, G.K., Mohamed, A., Chen, P., Carney, L.H., Lu, J., Wu, J., Chang, E.F., 2023. Dissecting neural computations in the human auditory pathway using deep neural networks for speech. Nat. Neurosci. 26, 2213–2225. https://doi.org/10.1038/s41593-023-01468-4
3. Liu, Y., Zhao, Z., Xu, M., Yu, H., Zhu, Y., Zhang, J., Bu, L., Zhang, X., Lu, J., Li, Y., Ming, D., Wu, J., 2023. Decoding and synthesizing tonal language speech from brain activity. Sci. Adv. 9, eadh0478. https://doi.org/10.1126/sciadv.adh0478
4. Lu, J., Li, Y., Zhao, Z., Liu, Y., Zhu, Y., Mao, Y., Wu, J., Chang, E.F., 2023. Neural control of lexical tone production in human laryngeal motor cortex. Nat. Commun. 14, 6917.
https://doi.org/10.1038/s41467-023-42175-9
5. Mesgarani, N., Cheung, C., Johnson, K., Chang, E.F., 2014. Phonetic Feature Encoding in Human Superior Temporal Gyrus. Science 343, 1006–1010. https://doi.org/10.1126/science.1245994